
Golden Section Search for Robust Regression
The most common method of fitting a linear model to data is ordinary least squares. In ordinary least squares we want to solve the following optimization problem
\[\begin{equation} \underset{\beta}{\text{minimize}} \quad {1 \over N}\sum_{i=1}^N (\beta^T x_i - y_i)^2 \end{equation}\]where \(N\) is the number of samples and \(\beta \in \mathbf{R}^d\). Often this will be written in matrix form as
\[\begin{equation} \underset{\beta}{\text{minimize}} \quad {1 \over N}||X\beta - y||_2^2 \end{equation}\]where \(X\in \mathbf{R}^{N\times d}\) and \(y\in \mathbf{R}^{N}\). In this formulation, least squares has a particularly nice closed form solution1
\[\beta^\star = (X^TX)^{-1}X^Ty.\]However, least squares is strongly affected by outlier data points. A more robust fitting procedure is least absolute deviations where we instead solve the optimization problem
\[\begin{equation} \underset{\beta}{\text{minimize}} \quad {1 \over N}\sum_{i=1}^N |\beta^T x_i - y_i| \end{equation}.\]Or written in matrix form
\[\begin{equation} \underset{\beta}{\text{minimize}} \quad ||X\beta - y||_1 \end{equation}.\]However, unlike least squares, there is no succinct closed form solution. The next section will introduce an iterative algorithm for solving this problem.
Coordinate Descent
Since the objective is the composition of an affine function with the absolute value function (which is convex), the least absolute deviation objective is convex. This means any local minimum we find will be a global minimum!
In typical applications, the \(\beta\) we’re solving for can be very high dimensional and hard to visualize. What if we could instead reduce the multi-dimensional optimization down to a series of 1D optimization problems?
This is the idea of coordinate descent. Instead of optimizing over all \(\beta_1,\ldots,\beta_d\) jointly, we cycle through each variable holding the others fixed and optimize over just one variable. For a specific coordinate \(k\), since all other \(\beta_j (j\ne k)\) are held fixed, the term \(\sum_{j\ne k} \beta_j x_{ij}\) is constant with respect to \(\beta_k\), so we can rewrite the residual as \(r_i = y_i - Σ_{j\ne k} \beta_j x_{ij}\). Now the subproblem becomes a single-variable optimization:
\[\begin{equation} \underset{\beta_k}{\text{minimize}} \quad {1 \over N}\sum_{i=1}^N |\beta_k x_{ik} - r_i|. \end{equation}\]Now that we have a simple 1D problem, we can graph an example to see what the objective might look like.
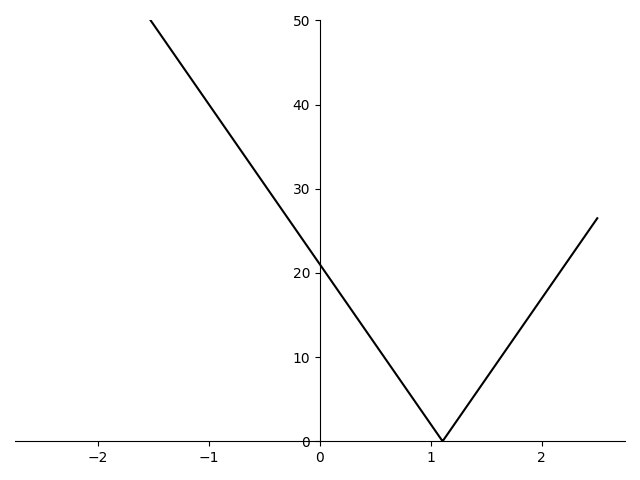
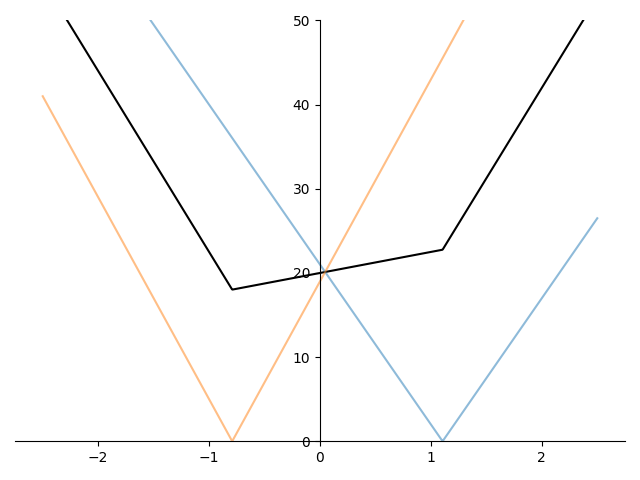
One observation worth noting from figure 1 is that the graph of the average of the absolute values has non-differentiable points (“kinks”) at the vertices of the original absolute value terms.
Figure 2 shows the average of several absolute value terms of the form \(\lvert \beta_k x_{ik} - y_i\rvert\) and we can see that the kinks in the graph of the mean occur at exactly the non-differentiable points of each absolute value term.
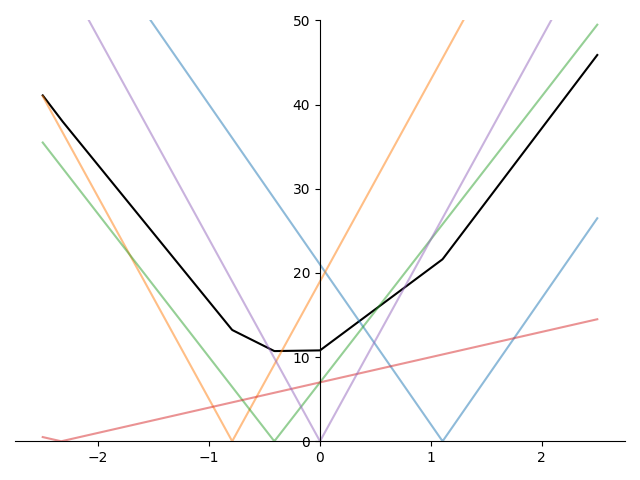
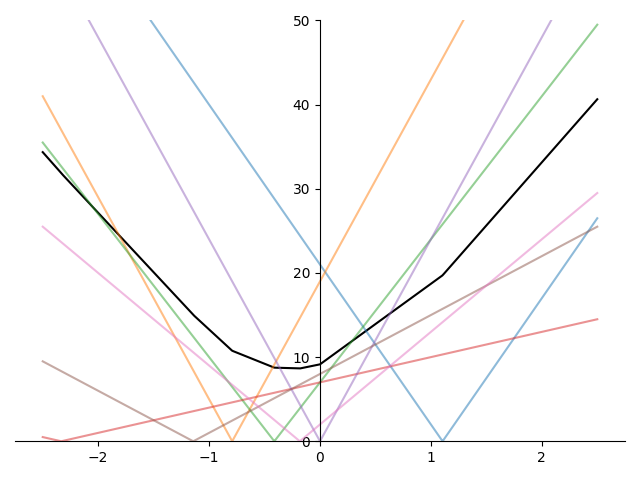
Since these kinks occur at the non-differentiable points of each absolute value term, they occur exactly when \(\beta_k x_{ik} - r_i = 0\). More precisely, kinks occur at values when \(\beta_k = r_i / x_{ik}\) for each \(i=1,\ldots, N\).
From the figure, it should be clear that the minimum will always lie between \(\min\{r_1/x_1, \ldots, r_n/x_n\}\) and \(\max\{r_1/x_1, \ldots, r_n/x_n\}\). If the objective is convex2 and we can bound the minimizer \(\beta_k^\star\), can we come up with an algorithm to iteratively shrink the bounds on the minimizer?
Interval Shrinking
We can start by initializing our algorithm with
\[\begin{align*} a &=\min\{r_1/x_1, \ldots, r_n/x_n\}\\ b &=\max\{r_1/x_1, \ldots, r_n/x_n\}. \end{align*}\]From the discussion above, it is guaranteed that \(a \le \beta^\star_k \le b\).
In order to iteratively shrink our interval \([a, b]\) in which the solution lies, we need to evaluate the objective at some points inside of the interval. We can define two new points to evaluate inside the interval by taking an offset from each of the endpoints.
Letting \(L=b-a\), the length of the bounding interval, we can define
\[\begin{align*} x_1 &= b - \rho L\\ x_2 &= a + \rho L \end{align*}\]where \(\rho \in (0.5, 1)\) ensures \(a < x_1 < x_2 < b\).
There are three possible configurations we can end up in as shown in Figure 3.
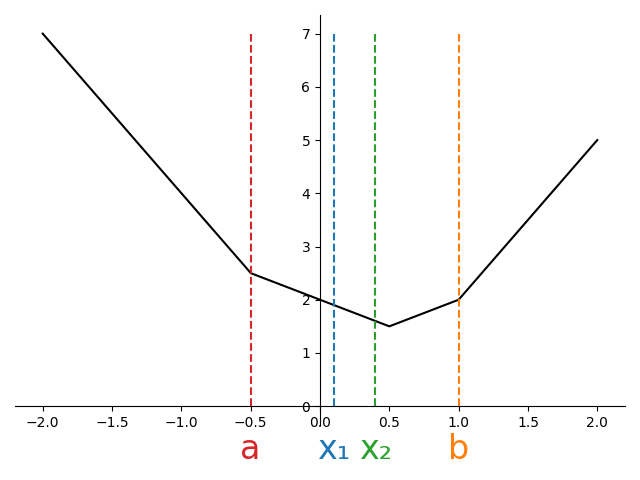
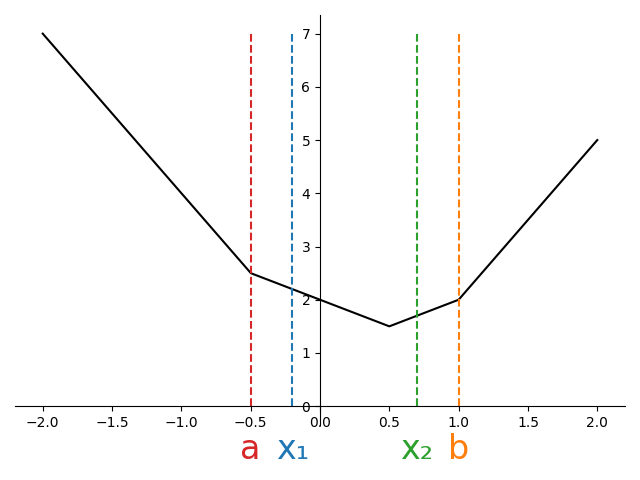
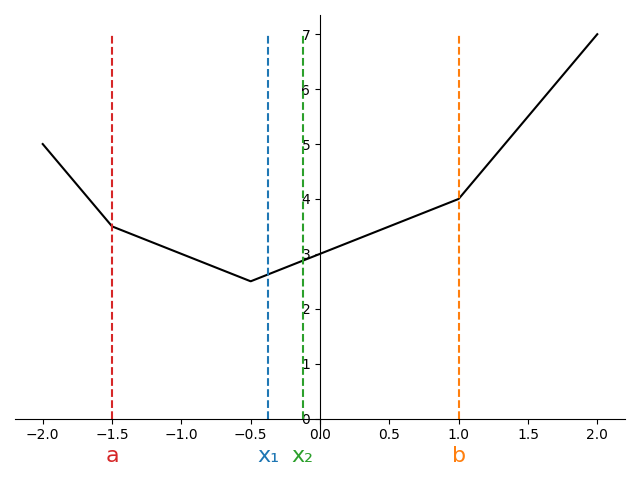
At the start of the algorithm, we’ll have found \(a\) and \(b\) in \(\mathcal{O}(N)\) time. For a given \(\rho\), we can then compute \(x_1\) and \(x_2\). Suppose we evaluate the objective at these new points, and find \(f(x_1) < f(x_2)\).
Looking at the first subplot of Figure 3, we can see that this scenario would be impossible. For a convex function, when both interior points are to the left of the minimum, the function is decreasing (negative subgradient), so \(f(x_1) > f(x_2)\)..
However, both the second and third subplot are potentially consistent with the observation that \(f(x_1) < f(x_2)\). If we knew we were in situation two, we could shrink the interval from \([a,b]\) down to \([x_1, x_2]\). On the other hand, if we knew were in situation three, we could shrink the interval to \([a, x_1]\).
Since we cannot distinguish between cases 2 and 3, we must retain all points consistent with either case, namely the union of the two intervals, \([a, x_2]\).
Running through the same argument for when \(f(x_1)\ge f(x_2)\) shows the interval can be reduced to \([x_1, b]\).
The full algorithm is then to initialize an interval \([a, b]\) to the smallest and largest values of kinks in the graph. Then compute \(x_1\) and \(x_2\) as described above and evaluate the objective to determine whether the solution lies in \([a, x_2]\) or \([x_1, b]\). This becomes our new interval and we repeat the procedure.
This algorithm is shown in the code below
Click for code
def interval_shrinking_minimize(
obj_fn,
a: float,
b: float,
rho: float,
n_iters: int = 5
):
assert b > a
assert n_iters >= 0
L = b - a
x1 = b - rho * L
x2 = a + rho * L
assert a < x1 < x2 < b
f_a = obj_fn(beta=a)
f_x1 = obj_fn(beta=x1)
f_x2 = obj_fn(beta=x2)
f_b = obj_fn(beta=b)
for _ in range(n_iters):
if f_x1 < f_x2:
b, f_b = x2, f_x2
else:
a, f_a = x1, f_x1
L = b - a
x1 = b - rho * L
x2 = a + rho * L
f_x1 = obj_fn(beta=x1)
f_x2 = obj_fn(beta=x2)
return {"a": (a, f_a), "x1": (x1, f_x1), "x2": (x2, f_x2) , "b":(b, f_b)}Notice how in the code above, obj_fn is called twice per iteration, once for \(x_1\) and again for \(x_2\).
Each objective evaluation incurs an \(\mathcal{O}(N)\) cost.
What if we could choose \(\rho\) so that we could reuse the objective evaluation on the next iteration?
Golden-Section
To avoid having to compute the objective function at two new points each iteration, we can attempt to set \(\rho\) so that one of our interior points (\(x_1\) or \(x_2\)) becomes an interior point in the next iteration.
At initialization we have
\[\begin{align*} x_1 = b - \rho (b-a)\\ x_2 = a + \rho (b-a) \end{align*}\]Suppose, \(f(x_1) < f(x_2)\) so that the interval in the next iteration is \([a, x_2]\). The new interior points will be
\[x'_1 = x_2 - \rho (x_2-a)\\ x'_2 = a + \rho (x_2-a)\]In order to ensure we can re-use \(x_1\) as one of our interior points on this iteration, we can set \(x'_2 = x_1\). To find a \(\rho\) satisfying this constraint, we can substitute the expressions on both sides
\[a + \rho (x_2 - a) = b - \rho(b-a).\]Substituting for \(x_2\) we have
\[a + \rho (a + \rho (b-a) - a) = b - \rho (b-a)\]and with some rearrangement and cancellation, we have
\[\rho (\rho (b-a)) + \rho (b-a) - (b-a)= 0.\]Dividing through by \(b-a\) gives the following condition that \(\rho\) must satisfy,
\[\rho^2 +\rho - 1= 0.\]Using the quadratic formula and discarding the negative solution, we find
\[\rho = {-1 + \sqrt{5} \over 2} \approx 0.61803.\]By setting \(\rho\) to this value, we ensure we can reuse the objective value at \(f(x_1)\) and only need to compute the objective at \(x'_1\) saving us \(\mathcal{O}(N)\) computation.
The widget in Figure 4 visually demonstrates the golden section algorithm and how points are reused from iteration to iteration.
The code below is a sample implementation of the golden section algorithm.
Notice how there is now only one call to obj_fn per iteration.
Click for code
def golden_section_minimize(obj_fn, a, b, n_iters: int = 5):
assert b > a
assert n_iters >= 0
L = b - a
rho = (-1 + 5**0.5) / 2
x1 = b - rho * L
x2 = a + rho * L
assert a < x1 < x2 < b
f_a = obj_fn(beta=a)
f_x1 = obj_fn(beta=x1)
f_x2 = obj_fn(beta=x2)
f_b = obj_fn(beta=b)
for i in range(n_iters):
if f_x1 < f_x2:
# When f(x1) < f(x2), x1 becomes the new x2 (reused from previous iteration)
b, f_b = x2, f_x2
L = b - a
x2, f_x2 = x1, f_x1
x1 = b - rho * L
f_x1 = obj_fn(beta=x1)
else:
a, f_a = x1, f_x1
L = b - a
x1, f_x1 = x2, f_x2
x2 = a + rho * L
f_x2 = obj_fn(beta=x2)
assert a < x1 < x2 < b, f"{a}, {x1}, {x2}, {b}, {i}"
return [a, x1, x2, b]The Golden Ratio
One remaining question is why this algorithm is referred to as the “golden” section algorithm. It turns out, it has a very close connection to the golden ratio \(\varphi\).
Two line segments are said to be in a golden ratio when the ratio of the longer segment to the shorter segment is the same as that of the sum of the lengths of the segments to that of the longer segment.
Concretely, suppose \(s\) and \(\ell\) are the lengths of two line segments with \(s < \ell\), then they are said to be in the golden ratio when
\[{s + \ell \over \ell} = {\ell \over s}.\]Denoting the ratio \(\ell/s\) as \(\varphi\), we have
\[\begin{align*} {1\over \varphi} + 1 &= \varphi\\ 1 + \varphi &= \varphi^2\\ \end{align*}\]Solving for \(\varphi\) using the quadratic formula and discarding the negative solution,
\[\varphi = {1 + \sqrt{5} \over 2}.\]This looks very close to our “optimal” \(\rho\) from the golden-section algorithm which was
\[\rho = {-1 + \sqrt{5} \over 2}.\]If we assume \(\ell=1\) and solve for \(s\) in \((s+\ell)/\ell = \varphi\), we have \(s = \varphi - 1= \rho\)! Solving \(\ell/s=\varphi\) for \(s\), we can also see that \(s = 1/\varphi\) further cementing the connection to the golden ratio.
Conclusion
We’ve seen how the golden section search elegantly solves 1D convex optimization problems by reusing objective evaluations across iterations, halving the computational cost compared to naive interval shrinking.
Recall that solving least absolute deviations regression—the robust alternative to least squares—requires solving:
\[\underset{\beta}{\text{minimize}} \quad {1 \over N}||X\beta - y||_1\]Since this is a convex objective without a closed-form solution, coordinate descent is a natural approach: cycle through each coordinate \(\beta_k\) and solve the resulting 1D subproblem. For each coordinate, we’re minimizing a sum of absolute value terms—a convex, unimodal function perfectly suited to this algorithm.
Surprisingly, this classical algorithm connects back to one of mathematics’ most famous constants, the golden ratio.
Footnotes
1: This formula only holds if \(X^TX\) is invertible. More specifically, when \(X\) is skinny (i.e. \(N>d\)) and full rank (i.e. \(\mathbf{rank}(X)=d\))
2: The algorithm will also work for quasiconvex functions (a.k.a unimodal functions) like \(f(x) = -e^{-x^2}\)